
Maschinelles Lernen vs. Deep Learning – die Zukunft entschlüsseln
Wenn von KI die Rede ist, fallen eine Reihe verwirrender Begriffe. Möglicherweise haben Sie ja schon einmal vom “Deep Learning” gehört, einer Unterkategorie des sogenannten maschinellen Lernens.
Was ist an Deep Learning eigentlich so tief?
Und wie können all diese verschiedenen Varianten von KI anhand von Daten lernen?
Die Geschichte des maschinellen Lernens
Versetzen Sie sich einmal in die Rolle eines Datenwissenschaftlers vor etwa 20 Jahren. Sie möchten mithilfe der bestehenden Technologien ein Problem lösen, für das es im Allgemeinen nur eine begrenzte Anzahl möglicher Antworten gibt. Ein paar Beispiele für solche Problemstellungen, die Sie lösen können, sind:
- Kreditwürdigkeit: Sie möchten herausfinden, ob jemand für einen von ihm beantragten Kredit qualifiziert ist. Hierfür müsste ein maschinelles Lernmodell auf Basis jahrzehntelanger Erfahrungen mit guten und schlechten Krediten trainiert werden, bevor man ihm den Kreditantrag einer Person einspeist. Dieses Modell würde daraufhin entweder “Ja” (Kredit gewähren) oder “Nein” (Kredit ablehnen) ausgeben.
- Erkennung von Spam-E-Mails: Sie möchten feststellen, ob es sich bei einer E-Mail um Spam handelt, und dazu trainieren Sie ein Modell zur Spam-Erkennung mithilfe von Daten. Dieses Modell würde dann entweder “Ja” (die E-Mail ist Spam) oder “Nein” (die E-Mail ist legitim) ausgeben.
Beide Beispiele nennt man Klassifikatoren, weil sie eine Antwort aus einer endlichen Menge von möglichen Klassifizierungen ausgeben.
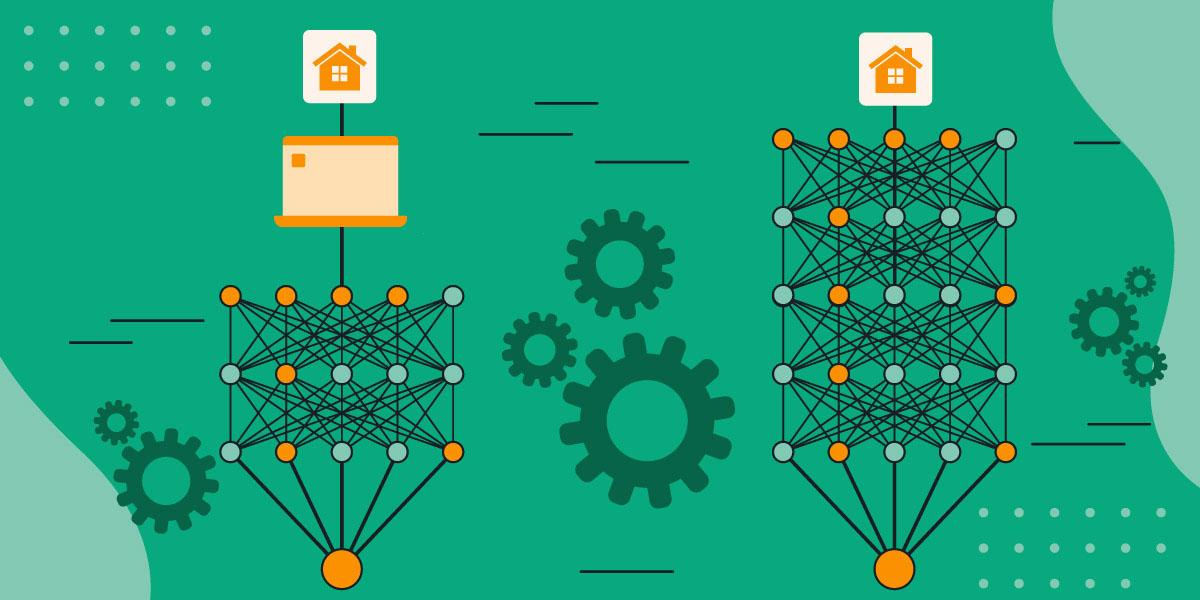
Andere Arten von Modellen lassen sich darauf trainieren, Fragen zu beantworten, wie z.B. wie viel das Haus einer Person aufgrund seiner Lage, Größe und seines Alters wert ist. Die Ausgabe ist eine einzige Zahl (und es liegen viele Datensätze über vergleichbare Häuser und deren Verkaufspreise vor).
Dies alles sind Beispiele nützlicher Anwendungsfälle für maschinelles Lernen, bei denen eine angemessene Menge an Lerndaten verfügbar ist. Diese Einsatzmöglichkeiten werden nur durch die Größe des Problems begrenzt, das es zu bewältigen gilt.
Maschinelles Lernen entwickelt sich weiter
Ein Jahrzehnt später sind die Ambitionen gewachsen: Jetzt sollen mithilfe des maschinellen Lernens weitaus komplexere Problemstellungen bewältigt werden! Als Datenwissenschaftler müssen Sie ermitteln, was zur Lösung dieser neuen Aufgaben erforderlich ist.

Und es zeigt sich, dass dazu drei Dinge nötig sind:
1. Deep Learning
Früher haben wir uns mit neuronalen Netzwerken beschäftigt: Reihen von virtuellen (weil mit Software geschriebenen) Knoten, die Muster in Daten erkennen und daraus lernen, wie sie verschiedene Dinge klassifizieren können. Damals wurden zur Lösung von Aufgaben im Bereich des maschinellen Lernens flache Modelle verwendet, die nicht viele Knoten hatten.
Um die heutigen komplexen Probleme zu lösen, bei denen es manchmal unendlich viele Antworten geben kann, mussten Datenwissenschaftler erkennen, dass Modelle viele Schichten mit vielen solcher Knoten benötigen, um die Aufgabenstellung zu lösen. Deshalb auch der Ausdruck Deep Learning. Der Begriff bezieht sich auf die Tiefe der Knotenpunkte in den zu erstellenden Modellen.
“Wir befinden uns heute in der Welt des Deep Learning.”
Damit Deep Learning funktioniert, reichen tiefe, also mehrschichtige Modelle allein jedoch nicht aus!
2. Big Data
Jede Art von maschinellem Lernen braucht Daten. Ohne Daten, aus denen man lernen kann, kann es auch kein Lernen geben. Bislang mussten in der Welt des maschinellen Lernens die Modelle anhand von Daten trainiert werden. Jetzt, wo es um viel komplexere Problemstellungen geht, werden natürlich auch viel mehr Daten benötigt. Hier zwei Beispiele für komplexe Aufgaben, die Datenwissenschaftler heutzutage zu lösen versuchen:
- Objekterkennung in Fotos: Damit ein Modell sämtliche Objekte auf einem Foto identifizieren kann, muss es alle denkbaren Objekte kennen, die sich auf dem Foto befinden könnten.
- Sprachliche Übersetzungen: Für eine Übersetzung vom Englischen ins Italienische müsste ein Model das gesamte Vokabular beider Sprachen kennen. Außerdem müsste es die Funktionsweise der Grammatik und die Redewendungen jeder Sprache kennen (“Hals- und Beinbruch”, z.B. vor einem Auftritt, dürfte sich nicht so einfach in andere Sprachen übertragen lassen).
Diese Modelle bräuchten einen riesigen Datensatz, damit sie gut funktionieren (größer als sämtliche Einträge in der Wikipedia)! Zum Glück leben wir in der Zeit von Big Data.
3. Grafikprozessoren (GPUs)
Zu guter Letzt benötigt man für das Training eines Modells mit derart großen Datenmengen enorme Rechenkapazitäten. Normalerweise arbeiten Computer mit einer CPU (Central Processing Unit). CPUs sorgen dafür, dass Computer schnell laufen, doch meistens verarbeiten sie nur eine Aufgabe auf einmal und sie sind für die Berechnung von Zahlen optimiert.
Bei den meisten Deep Learning-Modellen wird mit sogenannten Vektoren gearbeitet. Einen Vektor kann man sich als Pfeil mit einer bestimmten Länge vorstellen, der in eine bestimmte Richtung zeigt. Vektoren lassen sich zwar addieren, subtrahieren und multiplizieren, aber bei einer CPU dauert das unglaublich lange.
“Ein Übersetzungsprogramm mit CPUs zu trainieren, würde mehrere Dutzend Jahre dauern. Das ist schlichtweg nicht praktikabel.”
Zum Glück entwickelte sich vor etwa 20 Jahren ein Markt für passionierte Computerspieler. Diese Menschen erwarteten immer bessere Grafiken bei ihren Spielen. Diese können 2D- und 3D-Grafiken hervorragend darstellen und lassen sich gut an verschiedene Bildschirmgrößen anpassen. Doch für die einzigartige Berechnung von Vektoren brauchte man eine andere Art von Chip.
So entstanden die Grafikprozessoren (“Graphics Processing Units”, GPUs), die bei der Vektorberechnung ausgezeichnete Ergebnisse liefern. Mehr noch, Vektoroperationen lassen sich gut parallel ausführen: Wenn zwei GPUs zusammenarbeiten, können sie eine Aufgabe doppelt so schnell erledigen. Ein Grafikprozessor kann Vektoroperationen tausendmal schneller durchführen als eine CPU, und es ist möglich, Hunderte oder Tausende von Grafikprozessoren parallel zu schalten.
Ein Übersetzungsprogramm lässt sich mit Hilfe von GPUs in einer relativ überschaubaren Zeit trainieren.
Der aktuelle Erfolg von KI
Nach jahrzehntelangen Misserfolgen und unerfüllten Versprechen (schließlich begann die KI-Forschung bereits 1956) kommt die künstliche Intelligenz jetzt endlich groß raus. Wir verfügen jetzt über riesige Datenbestände (von denen ein Großteil öffentlich zugänglich ist), intelligente Datenwissenschaftler und GPUs für die Vektormanipulation.
Man stelle sich vor: Zahlreiche Problemstellungen, mit denen die Menschheit seit Jahrhunderten zu tun hat, ließen sich mithilfe von KI möglicherweise lösen.