
Computer vision: How AI models see and understand images

What is computer vision?
Computer vision is a field of artificial intelligence that enables computers to interpret and understand the visual world by processing images, video, and other visual inputs. Using deep learning models trained on large labeled image datasets, computer vision systems can identify objects, classify scenes, detect anomalies, and extract structured meaning from unstructured visual data. It powers applications ranging from facial recognition and automated quality inspection to AI-driven image search in digital asset libraries.
Marketing resource management (MRM) combines tools and processes that enable marketing teams to plan, execute, and measure campaigns with greater efficiency.
How does computer vision work?
What kind of magic is involved in letting a computer see images? Actually, it is not that magical: to an AI model, a byte of data is a byte of data. It might represent one pixel of an image, or part of a digital sound file, or one character of a text file: it all looks pretty much the same to the computer.
Certainly, some flavors of AI models work better on images, and others on sound, but for the most part, the ability for an AI model to do a good job at seeing photos and hearing audio is dependent on the training set — a principle that Fei-Fei Li helped establish through her large-scale labeled image research at Stanford.
In training, the model looks through your training set over and over. Each time the model looks through your data set is called an epoch, and during each epoch, the model makes small corrections to how each node processes your data until the results stop getting better.
Then, you graduate to start using the model, feed it an image it has never seen before, and see if you get a correct answer.
Of course, it is somewhat trickier than this. If you keep training a model with your training set too long, it overfits. Overfitting is when a model does a great job on your training set but when you show it something it hasn’t seen before (but ought to know about), it cannot generalize.
One of the challenges is understanding why these models work. We have done some work to understand what excites each node inside these models, but we also understand the model, during training, decides for itself what matters in its training set.
In general, the first layers seem to get excited by large features and then deeper layers pick up finer details, like this:
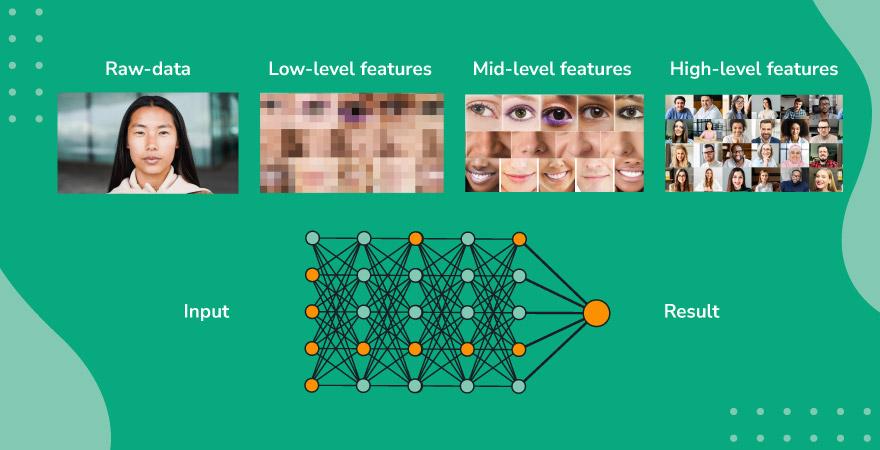
By 2017, teams competing in the ImageNet challenge were hitting 95% accuracy — but in the contest, they only had to make the right choice out of 1,000 categories.
Let’s move on to how a computer actually understands and categorizes images.
Computer vision and n-dimensional vectors explained
How do we get an AI model to understand a complicated picture?
Complicated images are said to have high dimensionality. In normal life, we are used to three dimensions (like the length, width, and height of your UPS package). However, mathematicians and computers think in ways that are not limited to normal, and so they can mentally work in spaces that have a thousand dimensions or more. Why is that useful?
Think of a photo of your dog on your couch in your living room, with pictures on the walls, and with a table with magazines on it. This is a fairly normal scene, but can you categorize it into only one category? It is way more complex than that.
Let’s think about this scene the way that mathematicians and computers do.
What if you take the photo, and you start with a dot in space? Then, you add an arrow sticking straight up from that dot, and its length is determined by if there is a dog in the photo (there is). Another arrow coming up from that dot but a few degrees to the right indicates if there is a cat in the photo (there is not, so that arrow is length zero). Then an arrow to the left denotes if there is a couch in the photo (there is, so that arrow has some length). An arrow facing down might denote if there is a table in the scene (there is, so that arrow has some length).
A photo rendered in this way could end up looking like this:

We call this an n-dimensional vector. As you might imagine, if you have enough of these pesky dimensions, you can pretty much represent anything that might be in any photo. Each photo will get its own n-dimensional vector, which you can think of as a digital fingerprint.
And this digital fingerprint is where things get very useful for anyone searching through photos using AI models trained on vast amounts of images.
You could find similar looking images by comparing their n-dimensional vectors. If their vectors are similar, the images are likely similar, too.
That is the next step in computer vision.