Image recognition software: What it is, how it works, and why it matters
What is image recognition technology?
Image recognition technology enables computers to identify and classify objects, people, text, and scenes by analyzing pixel patterns in digital images. At its core, image recognition software automatically describes visual content, including locations, backgrounds, people, behavior, and text, making large image collections searchable and organized at scale.
Image recognition applications includes many functions, including facial recognition for security and access control, diagnosing diseases from medical scans, and visual search for products.
How image recognition algorithms work
Modern image recognition algorithms rely on machine learning and deep learning techniques to analyze pixel values and extract meaningful features from digital images. A well-designed image recognition algorithm processes visual data (the raw pixel information captured in photos and videos) and translates it into structured, meaningful output. Where traditional machine learning required engineers to perform manual feature extraction and define rule-based algorithms, today’s deep learning models learn relevant features directly from raw image data, dramatically improving accuracy and scalability.
Image recognition systems are built to recognize images across a wide range of subjects, conditions, and formats. Inter-class variations, where some objects might vary in shape, size, and structure but can still belong to the same class, complicate image recognition. This is one of the core challenges that advanced models are designed to overcome.
Fundamentals of computer vision
Computer vision is the field that makes image recognition work. It gives machines the ability to analyze images and videos and make sense of what they’re seeing, whether that’s identifying a face in a crowd, detecting a product defect on an assembly line, or understanding a complex medical scan.
Computer vision technology powers everything from AI facial recognition systems and surveillance systems to self-driving vehicles, and its applications continue to expand across nearly every industry. Computer vision applications also increasingly run at the edge. Edge AI processes images locally on devices, enhancing privacy and reducing latency compared to cloud-based solutions, an important consideration for security and real-time use cases.
Computer vision tasks and techniques
Computer vision tasks rely on techniques like feature extraction, object detection, and image segmentation to break visual data into components that machine learning models can process and classify. Identifying the key features within an image (the edges, shapes, textures, and spatial relationships that define what an object is) sits at the heart of every computer vision workflow.
Deep learning in image recognition
Deep learning has transformed what image recognition models can do. Unlike earlier approaches that relied on manually engineered features, deep learning models automatically learn to recognize patterns, textures, shapes, and spatial relationships from training data.
Deep learning techniques such as convolutional neural networks (CNNs) have become the go-to architecture for image recognition tasks. A deep learning approach enables models to automatically extract features from raw image data rather than relying on manual specification. Deep learning models continue to improve as training datasets grow.
Python is a popular programming language for implementing image recognition due to its extensive libraries for artificial intelligence, and APIs can be used to access image data from cloud services for image recognition applications.
Model training and image data
The more diverse and high-quality the training data, the more robust the resulting model. Data annotation (labeling objects of interest in images) is essential to the model training process, and the performance of image recognition models depends directly on it. Engineers also preprocess images by normalizing pixel values to a standard range, typically between 0-1 or -1-1, to improve model stability and accuracy. Once a machine learning model has been trained, it can be deployed to accurately classify objects and interpret new images it has never encountered before.
Convolutional neural networks (CNNs)
Convolutional neural networks are the specialized deep learning architecture behind most modern image recognition work. CNNs are designed around how visual information is naturally structured: their convolutional layers act as pattern detectors, scanning digital images to identify edges, textures, and shapes. Each layer uses an activation function to introduce non-linearity, allowing the neural network to learn complex visual representations. Feature maps produced at each stage capture increasingly abstract information, which is then passed through pooling and fully connected layers to produce a final classification or detection output.
CNNs give teams all the tools needed to tackle a wide range of image recognition tasks, including image classification, object detection, segmentation tasks, and recognizing objects across varied conditions. They serve as the backbone of more advanced architectures like the Faster Region-Based CNN (Faster R-CNN), a leading approach for real-time object detection that uses a Region Proposal Network (RPN) to efficiently generate bounding boxes around detected objects.
Deep neural networks built on CNN architectures power applications across medical imaging, facial recognition, autonomous vehicles, security surveillance, and manufacturing quality control.
How CNNs extract features
What makes convolutional neural networks powerful is their ability to automatically extract features from raw image data. Engineers don’t need to specify what to look for; the features models learn emerge directly from labeled images during training, making CNNs far more adaptable than earlier approaches.
Traditional machine learning vs. deep learning
Support Vector Machines (SVMs) are a class of supervised machine learning algorithms used for classification tasks in image recognition, but they require carefully engineered input features. Similarly, the Histogram of Oriented Gradients (HOG) is a feature extraction technique used for object detection and recognition that works well in constrained conditions but lacks the flexibility of deep learning at scale.
Object detection and object recognition
Object detection and object recognition are closely related but distinct image recognition tasks. Object recognition identifies what an object is; it allows a system to understand images by mapping visual patterns to known categories. Object detection goes further, locating where objects are present in an image, drawing bounding boxes around them and classifying each detected instance. Together, these capabilities allow systems to identify objects and interpret entire scenes in real time.
Object detection algorithms like Faster R-CNN and YOLO use grid cell-based approaches and anchor boxes at multiple aspect ratios to detect and classify multiple objects in a single pass. These systems also support medical image analysis, where detecting objects such as tumors or lesions in scans requires precision and speed.
Detecting objects accurately in real-world conditions (varying lighting, unusual camera angles, or partial occlusion) remains one of the core challenges in image recognition systems. Researchers address this with techniques like data augmentation, transfer learning, and adversarial training to improve a model’s ability to generalize beyond the training process.
Real-time object detection
Real-time object detection is essential in applications like autonomous driving and security surveillance, where systems must process continuous streams of visual data with minimal latency. These systems must reliably identify objects across new images as conditions change, making robust model training and diverse labeled images critical to performance.
Optical character recognition and natural language processing
Image recognition extends beyond objects and faces. Optical Character Recognition (OCR) converts printed text in images into digital format, used in applications ranging from banking and invoice processing to real-time translation. OCR is one of the earliest and most widely deployed forms of image data extraction, and it continues to evolve alongside deep learning.
Natural language processing (NLP) increasingly works hand-in-hand with image recognition, enabling systems to understand images not just visually but semantically. NLP powers features like natural-language image search, automatic caption generation, and the ability to query visual content using plain text descriptions.
Facial recognition
Facial recognition is a specialized and widely deployed form of image recognition. It is widely used in security and surveillance to identify individuals from video feeds, enabling continuous monitoring of sensitive areas. Facial recognition systems apply deep learning to detect, align, and match faces against reference datasets, working reliably even under varying lighting conditions, angles, and partial occlusion.
Facial recognition for security and access control
Beyond security surveillance, face recognition is used in access control, customer identity verification, photo organization in consumer apps, and media asset management. Facial recognition also plays a key role in making large video libraries searchable, identifying and tracking individuals across hours of footage.
Key applications of image recognition technology
Image recognition technology is now embedded in workflows across industries:
| Industry | Application |
|---|---|
| Security and surveillance | Image recognition is used in security to identify criminals or victims and detect weapons in sensitive areas like airports, enabling real-time threat detection through continuous monitoring of video feeds. |
| Medical imaging | Image recognition assists healthcare professionals in analyzing X-rays, MRIs, and CT scans to detect anomalies that the human eye might miss, enabling faster and more accurate diagnosis. |
| Autonomous vehicles | Image recognition technology is used in autonomous vehicles to analyze real-time video feeds and navigate through traffic, detecting and classifying objects on the road including pedestrians, vehicles, and traffic signals. |
| E-commerce and visual search | Image recognition identifies favorite products of online shoppers and suggests new items based on previous views; image retrieval enables efficient content-based search across large product catalogs. |
| Manufacturing and quality control | Quality control in manufacturing employs image recognition for inspecting products for defects during assembly, reducing errors and improving throughput. |
| Fraud detection | Identifying patterns and anomalies in image data to flag suspicious documents, transactions, or identities. |
| Social media | Social media platforms use image recognition to suggest tags in photos and moderate content by filtering inappropriate images. |
| Agriculture | Using drone imagery and image recognition models to monitor crop health, assess plant stress, and optimize irrigation. |
Challenges in image recognition
Despite significant advances, image recognition systems still face meaningful challenges. Gathering sufficient labeled images for model training is time-consuming and costly. Deep learning techniques tend to work best with large, diverse training datasets, and building those datasets requires extensive data annotation.
Common obstacles for image recognition models
Models need exposure to varied sample images during training to learn the relevant features that remain consistent across different contexts: lighting conditions, backgrounds, and viewpoints. Real-world conditions (unpredictable lighting, unusual angles, or objects blocking the view) can degrade the performance of a trained model that performed well in controlled settings.
Object scale is another complication: small objects might not have enough detail for recognition, while overly close objects might appear distorted or too large for the model to classify correctly. Detecting objects reliably across new images that differ from the training distribution remains an ongoing challenge. Adversarial attacks can deliberately manipulate input images to fool image recognition algorithms, a growing concern in security-critical applications.
Researchers and engineers address these issues through transfer learning (adapting pre-trained models to new domains), data augmentation (artificially expanding training datasets), and adversarial training (exposing models to manipulated sample images during the training process).
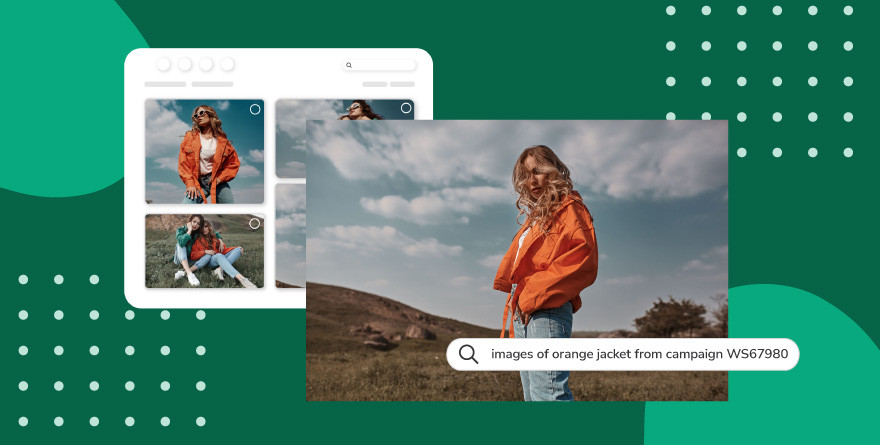
From basic image recognition to AI Visual Search
Standard image recognition software can tag images, identify objects, and flag content; and for many use cases, that’s enough. But for teams managing growing digital asset libraries, basic auto-tagging and object detection only go so far. Finding the right asset still requires knowing what metadata exists, remembering what tags were applied, or manually browsing through folders.
This is where more advanced applications of image recognition technology start to shine. Modern deep learning systems, built on convolutional neural networks, feature extraction, and visual similarity modeling, can do much more than label what’s in a photo. They can understand context, surface visually similar content, analyze video frame by frame, and even recognize individuals across thousands of images.
Take AI-powered visual search tools as an example. Instead of relying on metadata or manual tags, these systems let you describe what you need in natural language and surface the most relevant results instantly. They combine visual similarity, metadata, and natural language processing into a single search experience — so you can find a specific shot not just by tag, but by what it actually looks like.
Tools like Canto’s AI Visual Search apply this kind of technology specifically to the way creative and marketing teams work with content. Underlying machine learning algorithms recognize patterns across an entire asset library, enabling the system to surface relevant photos and videos based on visual data alone. Capabilities like frame-level video search, facial recognition across a full content collection, and duplicate detection help teams stay organized and get more value from every asset they produce.
For teams dealing with the explosion of content from generative AI and multi-channel campaigns, this represents a meaningful evolution from image recognition as a standalone feature to image recognition as a foundation for smarter, faster content workflows.
Why companies use image recognition software
Companies with growing image collections use image recognition software to manage the volume of tagging and labeling required across their libraries. Automated tagging increases search functionality and image retrievability, while superior image organization reduces potential copyright errors and accelerates project completion.
Beyond organization, image recognition technology enables computers to identify product defects, helps medical professionals spot anomalies, and is integral to the development of autonomous vehicles, making it one of the most consequential technologies in modern operations. Image recognition can speed up tedious tasks and process images faster or more accurately than manual image inspection, freeing teams to focus on higher-value work.
Image recognition work across industries
The efficiency gains compound across the business: when teams spend less time searching for assets, they have more time for high-value creative and strategic work. And when AI handles the image data layer, brands can maintain consistency, enforce compliance, and repurpose their best-performing content faster across platforms and campaigns. Image recognition technology enhances safety and improves customer experiences across various industries.
